
Introduction to Large Language Models (LLMs)
Hey there, tech enthusiasts and curious minds! Let’s talk about Large Language Models—or LLMs, as the cool kids call them. Now, I know what you might be thinking: “Oh great, another tech acronym! Is it something I should fear, like AI taking over the world? Or something I should love, like AI writing my work emails?” Well, buckle up because we’re about to unravel the magic (and madness) of LLMs in a way that’s both fun and informative.
What are Large Language Models (LLMs)?
Imagine you’re at a party, and there’s this one friend who seems to know everything. You ask them anything—how to make lasagna, why the sky is blue, or even the meaning of life—and they have an answer for it all. That’s a Large Language Model for you! LLMs are essentially super-smart algorithms trained to understand and generate human-like text. They’re the engines behind chatbots, voice assistants, content generators, and even that annoyingly good autocorrect on your phone.
Think of an LLM as a glorified storyteller—it has read literally everything (well, almost) on the internet and can answer your questions, make predictions, or even generate creative content on the fly. Whether you’re wondering what would happen if dinosaurs roamed the earth today or if you need some lines for your latest rap battle, an LLM is your go-to.
Where does LLMs fit in the world of Artificial Intelligence?
The field of AI is often visualized in layers:
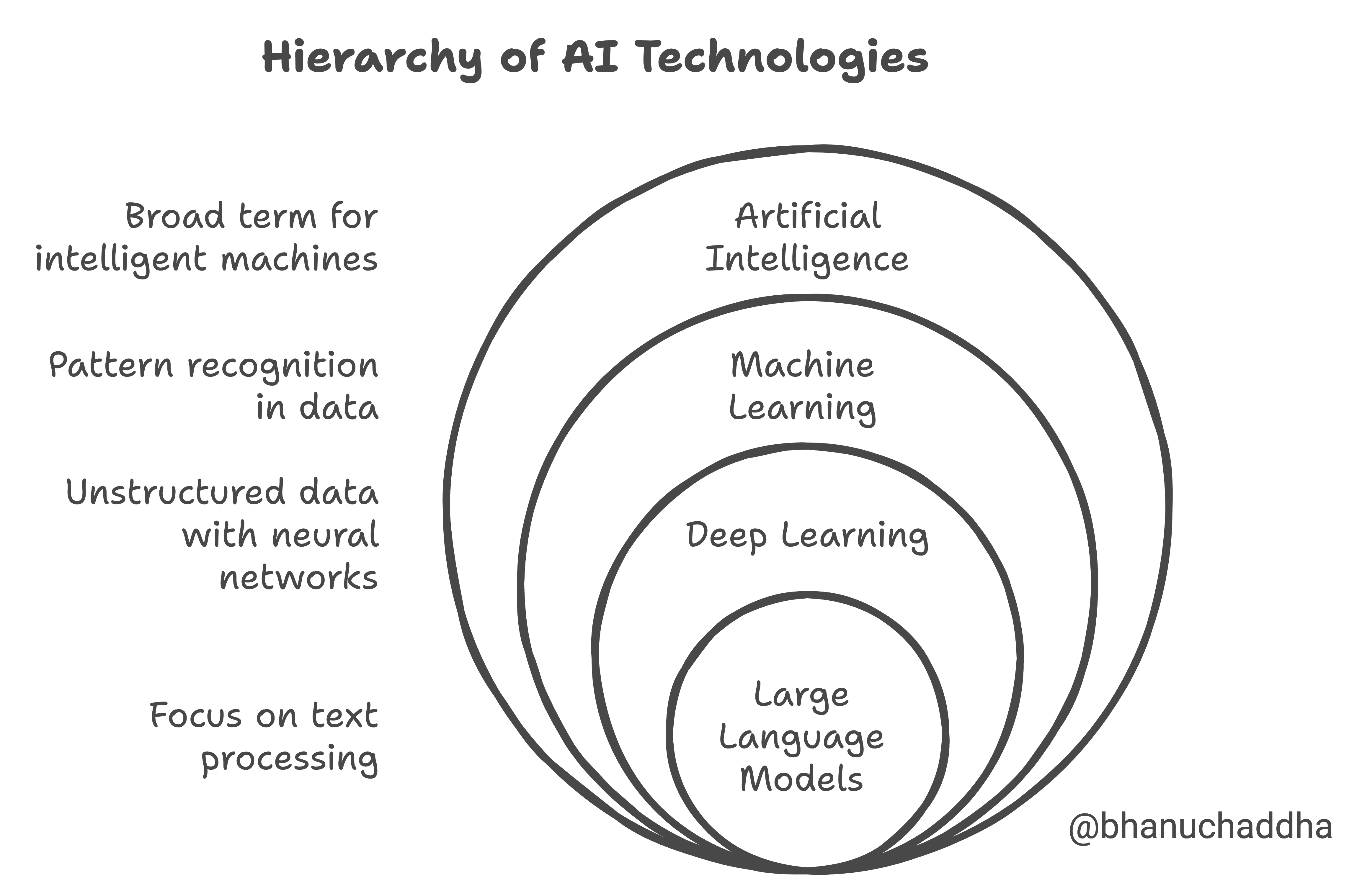
- Artificial Intelligence (AI) is very a broad term, but generally it deals with intelligent machines.
- Machine Learning (ML) is a subfield of AI that specifically focuses on pattern recognition in data. As you can imagine, once you recoginze a pattern, you can apply that pattern to new observations. That’s the essence of the idea, but we will get to that in just a bit.
- Deep Learning is the field within ML that is focused on unstructured data, which includes text and images. It relies on artificial neural networks, a method that is (loosely) inspired by the human brain.
- Large Language Models (LLMs) deal with text specifically, and that will be the focus of this article.
The Key Components of LLMs
Let’s break down what makes an LLM so darn impressive. Just like a great dish, it’s all about the ingredients. Here are the key components: Understanding these components is crucial, as we will cover the internal workings of LLMs in our next blog.
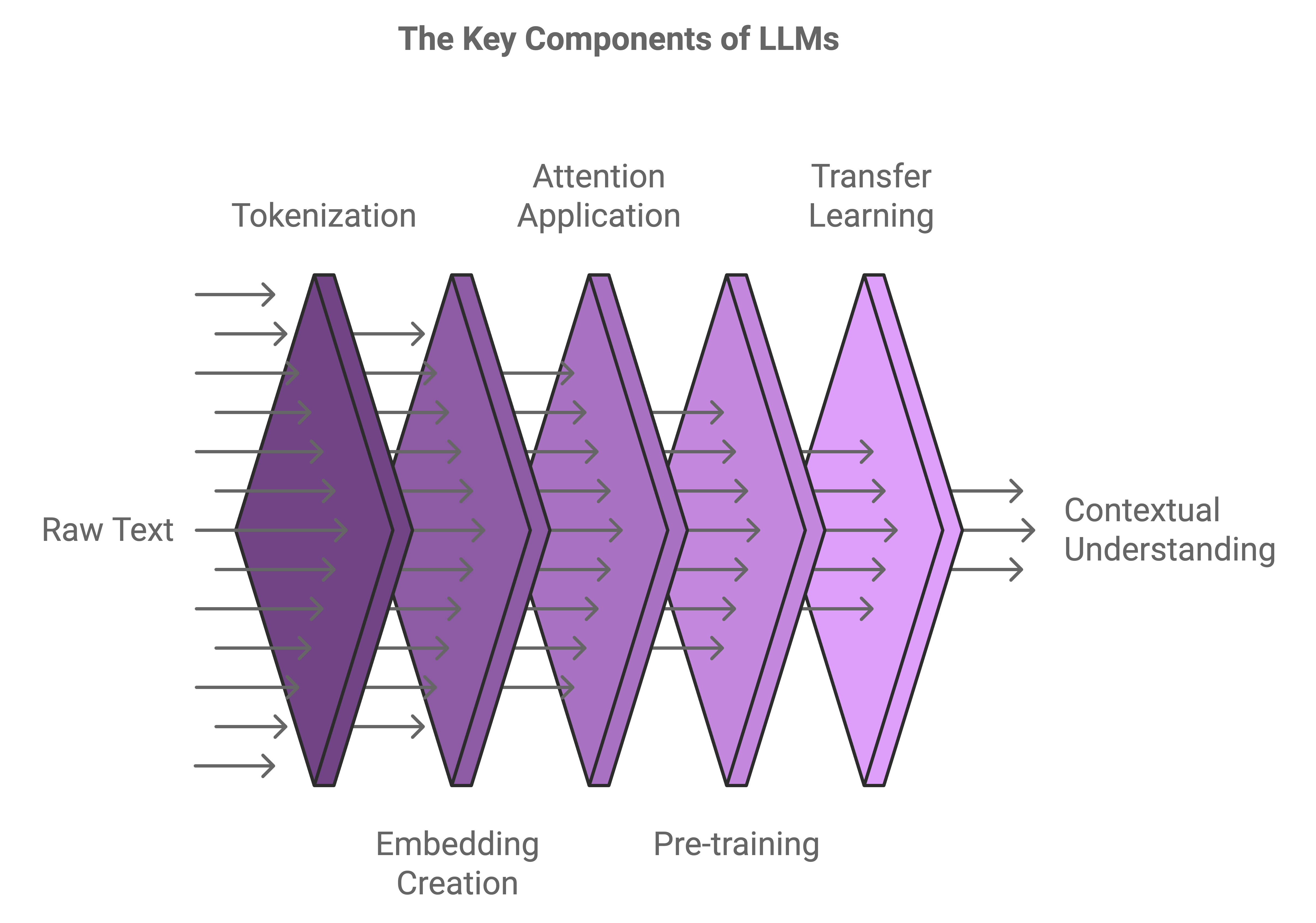
- Tokens :
Tokens are the fundamental building blocks that LLMs use to process text. In natural language processing, a token can be a word, part of a word, or even a character, depending on how the text is segmented. The process of tokenization involves splitting a text into these smaller units to allow the model to understand and analyze it effectively. For example, the sentence “ChatGPT is awesome!” might be tokenized into “Chat,” “G,” “PT,” “is,” and “awesome.” These tokens are fed into the model to create a structured representation of the input text. Tokenization enables the model to capture semantic patterns and relationships, which ultimately contribute to its ability to generate coherent responses. For Simplicity:
Tokens are like breaking down sentences into smaller pieces, such as words or even parts of words. By understanding these smaller pieces, the LLM can understand and make sense of whole sentences. - Embeddings :
Embeddings are dense vector representations of tokens that encode their meaning in a high-dimensional space. In this representation, each token is transformed into a vector of numbers, which captures the semantic properties of the word. Embeddings allow LLMs to understand relationships between words based on their context. Words that are similar in meaning, such as “king” and “queen,” or “happy” and “joyful,” will have vector representations that are close to each other in this high-dimensional space. The process of generating embeddings involves training the model on vast amounts of text data, enabling it to learn these relationships and provide contextually accurate responses. Embeddings play a critical role in LLMs as they help the model understand and predict language patterns beyond just individual words, allowing it to grasp context, nuance, and even complex word associations. This is what makes LLMs capable of handling intricate language tasks such as answering questions, translating text, or generating creative content. - Attention Mechanism :
The Attention Mechanism is a core component of transformer-based models like LLMs. It allows the model to dynamically focus on specific parts of the input text that are most relevant to predicting the next token or generating the output. Essentially, attention assigns different weights to different tokens in the input sequence based on their relevance to the current context. This process helps the model prioritize important information while ignoring irrelevant parts. In transformer models (which we would cover in the next blog), the self-attention mechanism is used to calculate the relationship between each word in a sentence with every other word. This allows the model to understand context more effectively, making it adept at dealing with long-range dependencies in text. For instance, in the sentence “The cat sat on the mat, and it quickly jumped off when it heard a noise,” the attention mechanism ensures that the model correctly associates “it” with “the cat,” thus preserving coherence in its understanding and generation. The self-attention mechanism allows LLMs to scale effectively to large datasets and handle complex tasks, making them highly capable of understanding intricate language structures and generating human-like responses. - Pre-training :
Pre-training is the initial phase where an LLM learns language patterns, grammar, and general knowledge from a large dataset. During this phase, the model is trained on diverse internet text using unsupervised learning, where it tries to predict the next word in a sentence. This process allows the model to understand language structure, syntax, and semantics, creating a foundational knowledge base. Pre-training is crucial because it enables the model to grasp the underlying principles of language, which can later be fine-tuned for specific tasks. - Transfer Learning :
Transfer learning in LLMs refers to the process where a pre-trained model is further trained (fine-tuned) on a smaller, more specific dataset to adapt it to a particular task. The idea is that the model’s general knowledge acquired during pre-training can be transferred to solve more specialized tasks efficiently. This approach not only saves time and computational resources but also improves the model’s performance on domain-specific problems by leveraging the existing knowledge.
Popular LLMs and Their Strengths
Now that we know what makes an LLM tick, let’s look at some famous models that are leading the charge in the AI revolution. These models are like celebrities in the world of machine learning—each with its unique strengths.
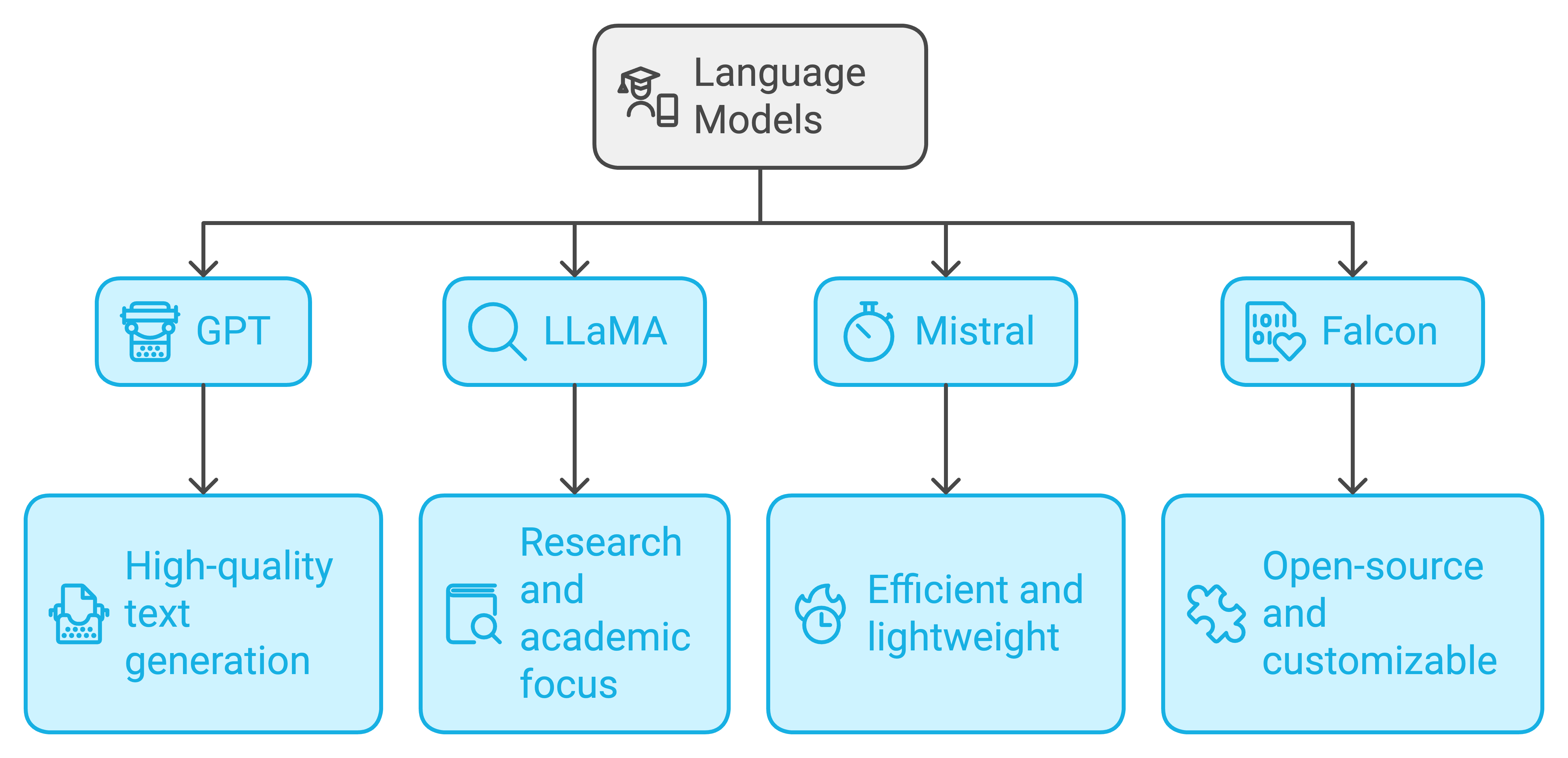
- GPT (Generative Pre-trained Transformer) :
GPT (Generative Pre-trained Transformer) by OpenAI is a state-of-the-art language model that leverages the transformer architecture to generate high-quality, human-like text. The model is pre-trained on a large corpus of internet text using unsupervised learning, which allows it to learn linguistic patterns, facts, and even reasoning abilities. GPT-4, for instance, has up to 175 billion parameters, making it one of the largest language models currently available. The model uses stacked layers of self-attention and feed-forward networks, which allow it to process and generate text efficiently. GPT’s versatility comes from its ability to be fine-tuned for specific tasks, making it suitable for applications ranging from chatbots to creative content generation. - LLaMA (Large Language Model Meta AI) :
LLaMA (Large Language Model Meta AI) by Meta is designed for research and academic purposes. LLaMA aims to make large-scale language models more accessible for study and experimentation, providing a model that is both transparent and efficient. Unlike proprietary models, LLaMA emphasizes accessibility, allowing researchers to analyze and modify the model’s architecture. LLaMA uses transformer-based technology similar to other LLMs but with optimizations that make it more lightweight, which allows researchers with fewer computational resources to experiment with state-of-the-art NLP technology. - Mistral :
Mistral is an efficient, lightweight language model optimized for performance with limited computational resources. It uses architectural improvements to maintain high performance while reducing the computational overhead compared to larger models. Mistral is ideal for scenarios where efficiency and speed are more critical than the massive scale of models like GPT-4. This model is designed to provide similar capabilities to larger models without requiring significant infrastructure, making it more accessible for applications where computational power is a limiting factor. - Falcon :
Falcon is an open-source language model developed in the UAE, positioned as a powerful alternative to proprietary LLMs. Falcon’s architecture is based on the transformer model, but it emphasizes scalability and ease of customization. By being open-source, Falcon allows developers and researchers to access, modify, and build upon the model freely, fostering innovation and collaboration in the AI community. Its capabilities are comparable to other leading LLMs, but with an emphasis on transparency and community-driven improvements.
| Feature/Model | GPT | LLaMA | Mistral | Falcon |
|---|---|---|---|---|
| Developer | OpenAI | Meta | Mistral AI | Technology Innovation Institute |
| Architecture | Transformer | Transformer | Optimized Transformer | Transformer |
| Parameters | Up to 175 billion | Varies (Research Focus) | Efficient, Medium Scale | Scalable, Community-driven |
| Training Dataset | Diverse internet corpus | Academic, Research | Efficiency-focused | Open-source, Transparent |
| Use Cases | General purpose (chat, | Research, Academic | High efficiency tasks | Customizable AI |
| creative content) | ||||
| Accessibility | Proprietary | Accessible for Research | Lightweight, Low-cost | Open-source |
| Performance | High-quality, versatile | Research-optimized | Resource-efficient | Customizable and scalable |
| Fine-tuning | Highly adaptable | Available for research | Limited due to resource | Easy due to open nature |
| Scalability | High | Medium | Medium | High |
| Customization | Limited | High | Medium | Very High |
| Community Support | Moderate | Low | Low | High |
Wrapping Up
Large Language Models aren’t just a fad—they’re changing the way we interact with machines. They can write stories, code apps, solve complex problems, or even help you brainstorm gift ideas for that friend who “has everything.” The magic comes from the combination of tokens, embeddings, and attention—working together to create a sophisticated understanding of language that’s almost (but not quite) human.
And while we’re not quite at the point where LLMs can understand the deep, existential crisis you face every Monday morning, we’re getting closer to an era where AI can genuinely help make our lives a little easier—one token at a time.
So next time you use a chatbot or watch as an AI autocorrects your messages, remember that behind the scenes, there’s a brilliant orchestra of tokens, embeddings, and attention working in tandem—a beautiful mess that somehow just works.
Whether you’re a developer, a researcher, or just someone fascinated by AI, the world of LLMs is full of opportunities and challenges. And as these models continue to evolve, one thing is certain: they’re here to stay, and they’re only going to get better. So why not dive in, explore, and see what these incredible models can do for you?

