Part-5: ReAct Is Where You Start, Not Where You Ship
Part 5 of a series on what actually goes into production agentic systems.
Part 1 – Most “AI Agents” in Production Are Demos With Extra Steps
Part 2 – Most “Agents” Are Workflows That Got Ideas
Part 3 – Most Agentic Projects Can’t Defend Their Own ROI
Part 4 – Most Multi-Agent Systems Shouldn’t Be
ReAct looks like an architecture. It is actually a debugging aid that escaped.
The original paper shipped a useful trick: make the model narrate its reasoning between tool calls so humans could watch it think. Somewhere along the way, “expose the reasoning” became “let the model decide every step, turn by turn,” and that became the default shape of agentic systems. We are living with the consequences. Most production “agents” are ReAct loops that should have graduated months ago and never did.

Caption: the three orchestration shapes on a single structure axis
The three orchestration patterns sit on one axis: how much of the control flow lives in the model versus in code. Most teams default to the left; most systems end up on the right.
The only question that matters
Strip away the framework debates and the three orchestration patterns reduce to one axis: where does the control flow live?
ReAct puts all of it in the model’s head. Each turn the model reads the history, picks the next tool, observes the result, and decides what to do next. The loop runs until it stops itself. The structure is whatever the model decides structure is, this time.
Plan-and-execute splits the work in two. A planner generates a multi-step plan up front, and an executor walks through it, optionally re-planning when things go sideways. The structure is written once, at the top, by a model that has not done any of the work yet.
Graph orchestration puts the structure in code. Nodes are functions, some of which call LLMs. Edges are explicit transitions between them. The model decides things inside nodes; the code decides which node runs next.
Every orchestration debate is a rerun of the question from Topic 2: who holds the control flow? ReAct puts it entirely in the model. Graph puts it entirely in code. Plan-and-execute tries for the middle and usually lands badly.
The email agent, three ways
Let’s say you are building an email-processing agent. It reads inbound messages, extracts structured information, looks up context from the CRM, drafts a reply, and routes anything ambiguous to a human.
As ReAct: one loop, one system prompt, a tools list with five or six entries (classify, crm_lookup, draft_reply, route_to_human, send). Each turn the model looks at the thread so far and picks the next tool. After a few turns it decides it is done and stops. Simple to write. Simple to misread.
As plan-and-execute: a planner reads the email and outputs a plan like “step 1: classify, step 2: look up customer in CRM, step 3: draft reply, step 4: route if confidence is low.” An executor runs the steps in order. If step 2 returns an unknown customer, the system has to re-plan, and the whole thing gets shakier with every re-plan.
As a graph: an explicit state machine. A classify node, a crm_lookup node, a draft_reply node, a route_to_human node, and edges between them. The classify node’s output determines which edge fires. The LLM is invoked inside individual nodes, but the flow between nodes is code.
Same problem, three shapes, wildly different failure modes.
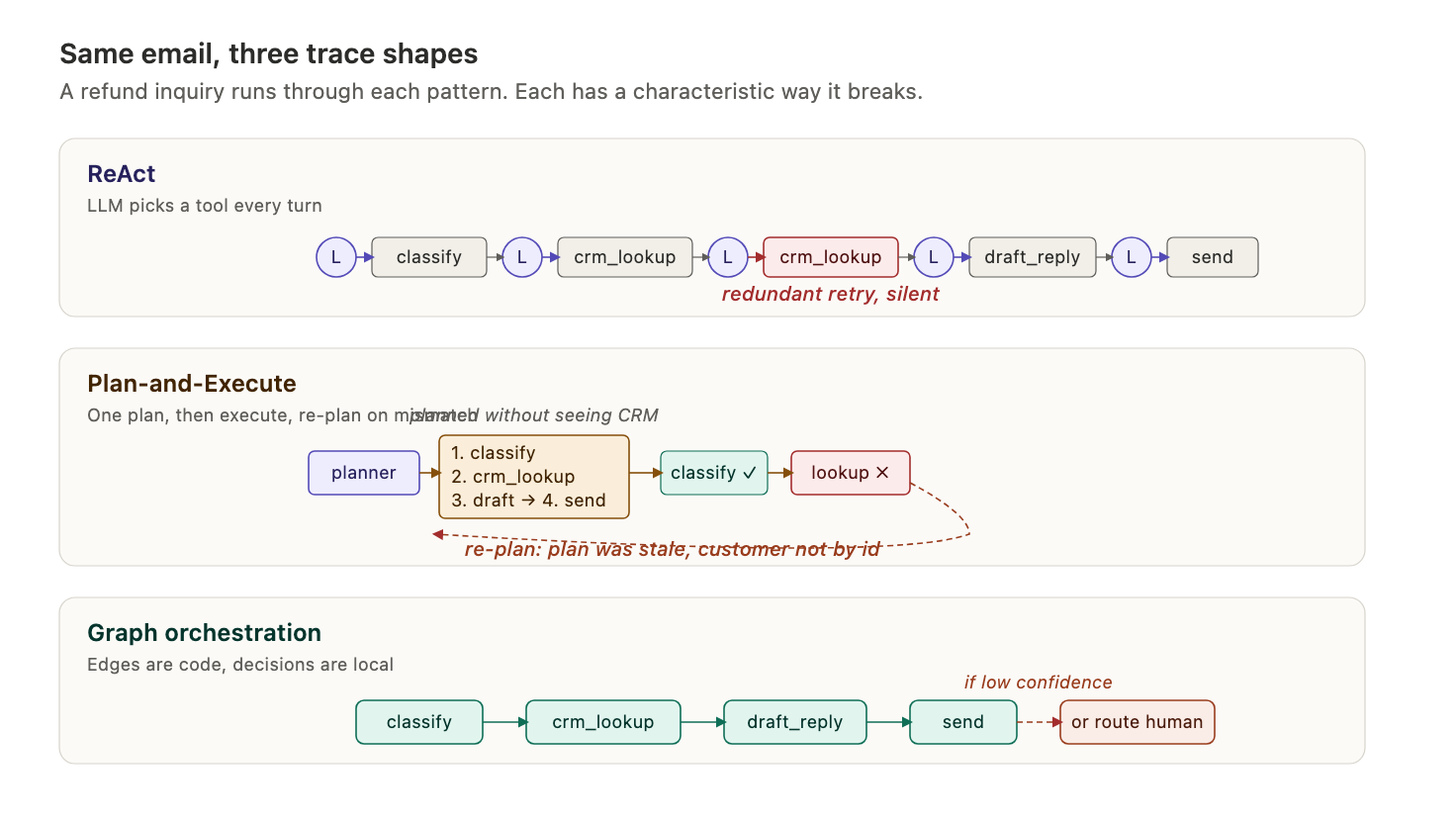
Caption: the email agent drawn as ReAct, plan-and-execute, and graph
Why each one fails
ReAct fails on tool surface. Every tool you add is another dimension the model reasons over on every turn. Five tools is fine. Fifteen tools is a coin flip. The failure mode is silent: the model does not crash, it just picks the wrong tool, or calls the right tool with bad arguments, or loops on the same tool three times before realizing the prior call already did the thing. Traces get long, latency compounds, and the team starts adding sentences like “only call send_email if you have already called draft_reply” to the system prompt. That prompt is now three thousand tokens of hedges. The ReAct loop is being patched into a workflow, one hedge at a time.
Plan-and-execute fails on contact with reality. Planning before doing sounds smart. In practice, the planner has no feedback from the world. It does not know what the CRM will return. It does not know the customer record is malformed. It writes a plan from the email alone, and the plan is stale the instant the first tool returns something unexpected. Teams bolt on re-planning and tell themselves they have solved it. Re-planning is ReAct with extra steps: you are calling the planner again after each observation, which is just ReAct with a more expensive inner call.
The one case where plan-and-execute genuinely earns its keep is long-horizon tasks where the action space is huge and verification is cheap. Deep research agents. Some agentic coding loops. If you are not in that shape, you are paying the tax for no benefit.
Graph orchestration fails on rigidity. The graph is strong because it is written down. It is brittle for the same reason. A new capability means editing the graph, reviewing the diff, redeploying. The team that loved the graph in month two is frustrated in month six, because “just add a step” now means a pull request. And if the graph drifts toward mostly LLM-decision nodes with dynamic edges, you have rebuilt ReAct in a framework that makes it harder to change.
The ReAct graduation
Watch a ReAct agent in production for three months. Pull up the traces and cluster them. You will find that three or four paths dominate. Email comes in, gets classified, CRM gets hit, reply gets drafted, sent or routed. That is eighty percent of traffic. The other twenty percent is weirder, but most of that clusters into another two or three paths. The long tail is real but small.
The team, watching this, will start adding shortcuts. “If the email is flagged as a refund, skip classification.” “Always look up the customer before drafting.” “Cap the number of tool calls at six.” Each rule is a small admission that the model did not actually need to decide that branch. Six months in, the ReAct loop is a graph wearing a costume. The costume is expensive: every turn still goes through the model to pick a tool the code already knows to call.
This is the pattern worth naming: the ReAct graduation. Teams converge to graphs. They discover the structure with ReAct and then fossilize it in code, because code is cheaper, faster, more reliable, and easier to change than a prompt that hedges against every branch.
The mistake is not starting with ReAct. ReAct is a great scaffold for figuring out what shape the problem has. The mistake is staying in ReAct after you have figured it out.

Caption: how a ReAct agent evolves into a graph over time
The framework trap
Teams rarely pick an orchestration pattern. They pick a framework, and the framework picks the pattern for them.
LangGraph looks like graph orchestration, and it is, right up until you write most of your nodes as “ask the LLM what to do next” and most of your edges as “use the LLM’s response to route.” Now you have a ReAct loop inside graph boilerplate, with the worst of both. You have paid the tax of writing down a graph and gotten none of the benefit of deterministic routing.
The tell: if deleting eighty percent of the graph nodes and replacing them with a single ReAct loop would produce a system that works the same, you did not need the graph. You needed a ReAct agent with a better prompt.
Framework choice is downstream. First decide how much of the route you trust the model to hold. Then the framework picks itself.
The thing nobody says out loud
“We are using ReAct” sounds sophisticated. “We built it as a graph” sounds like a workflow. And per Topic 2, workflow is the label nobody wants, because it smells less like an agent and more like the 2018 Python script the AI team replaced.
So teams keep ReAct long past its usefulness. The trace viewer is a mess, the prompt has twelve “do not” clauses, the latency is embarrassing, and nobody wants to be the person in the architecture review who says “let’s turn this into a graph with four nodes.” Because a graph with four nodes is not AI, apparently. It is just software.
This is the same organizational pressure that pushes teams toward calling workflows agents. The fix is also the same: name the shape honestly, pick the lowest-agency version that actually works, and let the label come last.
What ships
The practical heuristic for the eighty-percent case: start as ReAct to discover the structure, move to a graph once the structure is stable, and stay in a graph unless something in the problem genuinely demands per-turn dynamism. Treat ReAct as a prototyping tool, not a target architecture. Treat plan-and-execute as a specialist pattern for long-horizon tasks with cheap verification, not a general one.
ReAct is where you start. Graph is where you end up. Plan-and-execute is the detour most teams take in between.
Coming Up in This Series
Next up: RAG done right: hybrid search, chunking, re-ranking. That closes out the foundations block and opens the quality block. Most RAG systems in production are a single embedding model, a single index, and a top-k retrieval that everyone agrees is “fine.” They are not fine. The gap between demo RAG and production RAG is where most agentic systems quietly lose their quality, and it is almost never the model’s fault.
If this resonated and you’re building production AI systems, follow along. The series covers the 21 things I think senior AI engineers and architects need to reason about: RAG pipelines, tool design, security, evaluation, cost, and the operational patterns that separate demos from systems you can actually run.

